hadoop, spark
In order to use Spark on windows you need to install winutils.exe and change some environment variables. Here is a nice fix.
Read more...
data warehouse, postgresql
Is PostgreSQL a good companion for a data scientist at a startup? At which maturity stage should it be used? Let’s find out!
Open Source ETL tool for data warehouse : Agile and SQL-based
Find more...
business, data warehouse, startup
At the foundation of deep analytics there is a nicely structured master table. Let’s see where a startup need to start.
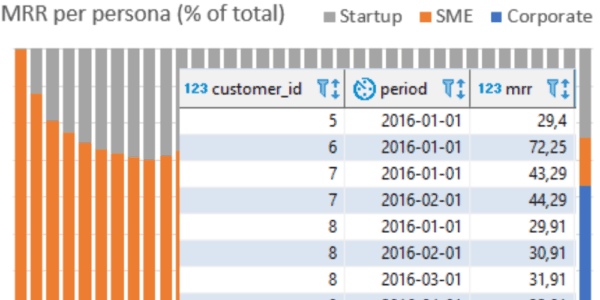
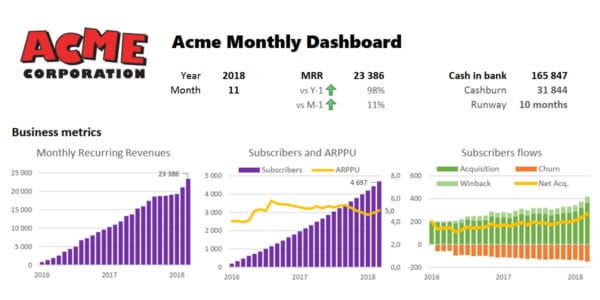
analytics, business, dashboard
Let’s review the book Hacking Growth Hacking Growth : How Today’s Fastest-Growing Companies Drive Breakout Success from a data science perspective.
analytics, business, dashboard, startup
A good dashboard is a tool to reflect on the business, find new questions and insights to achieve growth. Get some tips.
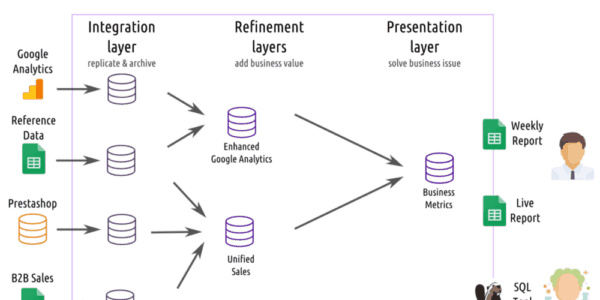
data warehouse
After years of analytics pratice, we came to a set of opinions on how data warehouses should be built.
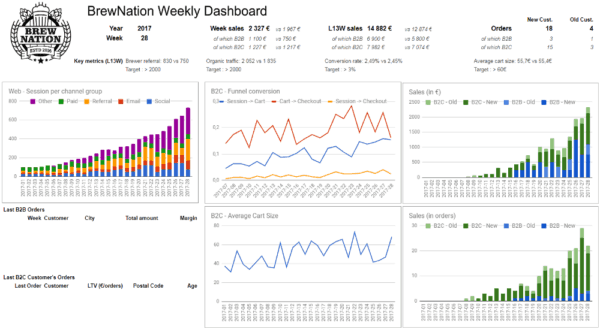
reporting, startup, use case
BrewNation figured how to get fast and affordable analytics with the help of DataIntoResults. Let’s see how it works.
Greenplum, hadoop, impala, pivotal hd
With the recent release of Pivotal HD, I wanted to check the current state of Hadoop SQL engines. SQL integration is growing in the Hadoop […]
In the age of big data, predictive analytics is all around us. Probably you have heard about the Netflix Prize, awarding US$1,000,000 to anyone capable of […]
data manipulation, hadoop
I’ve spent some time lately to dig into the Hadoop ecosystem both from a product survey and some hands on. Here is some remarks about […]